Scoping a Local-First Image Archive
For years, I’ve been thinking about how we store and access our digital files, especially photos. Everything is moving to the cloud, with complex systems/applications that abstract away what should be simple: a folder of images.
I don’t want that.
I want something simple. Something that doesn’t need a server, doesn’t rely on a database, and doesn’t lock me into any specific ecosystem. I want something that just works with files and folders, something that can disappear tomorrow without leaving a trace or be run once and the result lives forever.
After a rough prototype using nodejs and seeing the value, this is a brain dump of why I want to build it better.
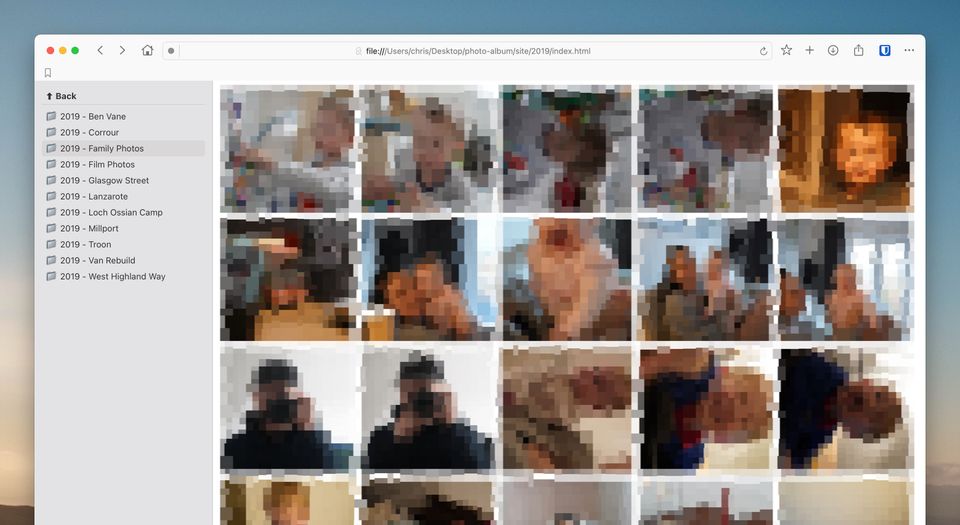
1. The Problem With Most Photo Solutions (Google Photos, iCloud Photos etc)
Photo organisation has become too complicated and focused solely on organisation - not archiving. I'm not hating on these services, they're fantastic for managing a working window of photos of your life but do we really want 10, 15, 20 year old photos stored on these?
- Everything assumes we want a database, AI, syncing and 100x features.
- Most systems will rename, sort, or move your images.
- Cloud-based solutions push you into subscription models and walled gardens (Google Photos, iCloud Photos, for example).
- If you stop using them, you lose your metadata, organisation, and edits - ultimately ending up with a messy export of unorganised chaos.
For non-technical people (and even for myself), this isn’t ideal. What happens to your files when you’re gone? If your family wants to browse your archive in 10 years, will they be able to?
This should be simple.
A well-structured folder, whether on a few external drives and/or backed-up remotely off-site, is already a great way to orgaise images. Why complicate it?
2. The Plain Text Movement: Files Are King
There’s a movement back to plain text. Notebooks, wikis, documentation—people are ditching databases and proprietary formats in favor of simple, readable files.
Why? Because files last longer than apps.
I want the same philosophy for images. The filesystem should be the structure—not some abstract interface on top of it.
- A folder is already a collection.
- A plain text file (
meta.md) can store optional metadata and is readable simply by opening it. - If you move or delete the app, nothing breaks.
This isn’t about reinventing the wheel—it’s about not overcomplicating it in the first place.
3. A Local-Only, Zero-Dependency Image Archive
The goal is a tool that:
- ✅ Works completely offline—just open the root index.html file in the folder in your browser.
- ✅ Requires no server or database—purely flat files.
- ✅ Never modifies or renames files—zero risk to your images, metadata and structure.
- ✅ Leaves no trace—if you delete the app, or purge the archive site, everything of yours stays intact.
- ✅ Uses just a single CSS file for styling—customisable with a minimal default.
Essentially, it’s just a static site generator for folders of images, that lives within your library. You could ignore it completely and still access your photos like normal, or use it when you feel the need.
4. Minimal JavaScript (Or None at All)
By default, it should be pure HTML and CSS and use browser features over eye-candy.
JavaScript should be optional and only for UX improvements like:
- A better folder tree UI.
- Lazy-loading large images.
- Small accessibility enhancements.
If JavaScript is disabled, nothing should break.
5. How It’s Structured
Folder Organisation
Instead of using a database, this project uses the filesystem as the database:
📂 Photos/
├── 📂 2024-Scotland-Trip/
│ ├── 🖼 image1.jpg
│ ├── 🖼 image2.png
│ ├── 📄 meta.md (Optional metadata)
│ ├── 📂 .thumbs/ (Auto-generated thumbnails)
│ ├── 📜 index.html (Auto-generated UI)
│
├── 📂 2023-Italy/
│ ├── 🖼 photo.jpg
│ ├── 📄 meta.txt (Plain text metadata)
│ ├── 📂 .thumbs/ (Auto-generated thumbnails)
│ ├── 📜 index.html (Auto-generated UI)
│
├── 📜 style.css (Global styles)
├── 📜 index.html (Root index)
📂 Folders = Categories
📄 meta.md = Optional metadata for each folder
📂 .thumbs/ = System hidden dot folders of auto-generated thumbnails to aid quicker loading of pages
No database, no external dependencies—just files. You can build it, stick it on an SSD and pick it up in 10 years time and it'll work.
6. How It Works
- A small background app watches the folder or triggered manually.
- When files are added or removed, it:
- Generates a static HTML index for each folder.
- Creates thumbnails (but never modifies the originals).
- Uses Markdown or plain txt files for metadata.
- Open the folder in a browser to browse the images.
No complex setup, no syncing, no extra nonsense.
7. Why Move Away from Node.js?
Right now, I have prototyped this with a Node.js script and it works, but it’s not ideal:
- 🚫 It’s bloated.
- 🚫 It requires installing dependencies.
- 🚫 Any UI would likely lean on Electron.
- 🚫 It’s not lightweight enough for a background process (looking at your Electron).
The goal is to rebuild it in Rust or Go, which will make it:
- ✅ A single, tiny executable (~5MB or less).
- ✅ Fast and low-memory—runs silently in the background.
- ✅ Zero dependencies—just open the app, provide a folder and run.
Rust would make it even faster, while Go would make cross-platform support simpler. Either way, the goal is a tiny, native app that just does its job and gets out of the way.
8. Final Thoughts: Keep It Simple
This project is opinionated but simple:
- Folders are the king—no databases, just files.
- Metadata is optional—stored as readable text.
- No tracking, no cloud, no bloat.
- Deleting the app leaves zero trace.
It’s just a lightweight way to browse folders of images—nothing more, nothing less.
I’ll start prototyping the Rust version soon. If this sounds interesting, let me know. 🚀